Defending Against Transfer Attacks From Public Models
November 2, 2023
TL;DR: We propose a new practical threat model, transfer attacks from public models (TAPM), and build a simple yet effective defense that provides higher robustness than adversarial training with almost no drop in the clean accuracy compared to undefended models.
Mentions: Twitter, r/MachineLearning - Reddit, AIModels.fyi
Authors: Chawin Sitawarin, Jaewon Chang*, David Huang*, Wesson Altoyan, David Wagner
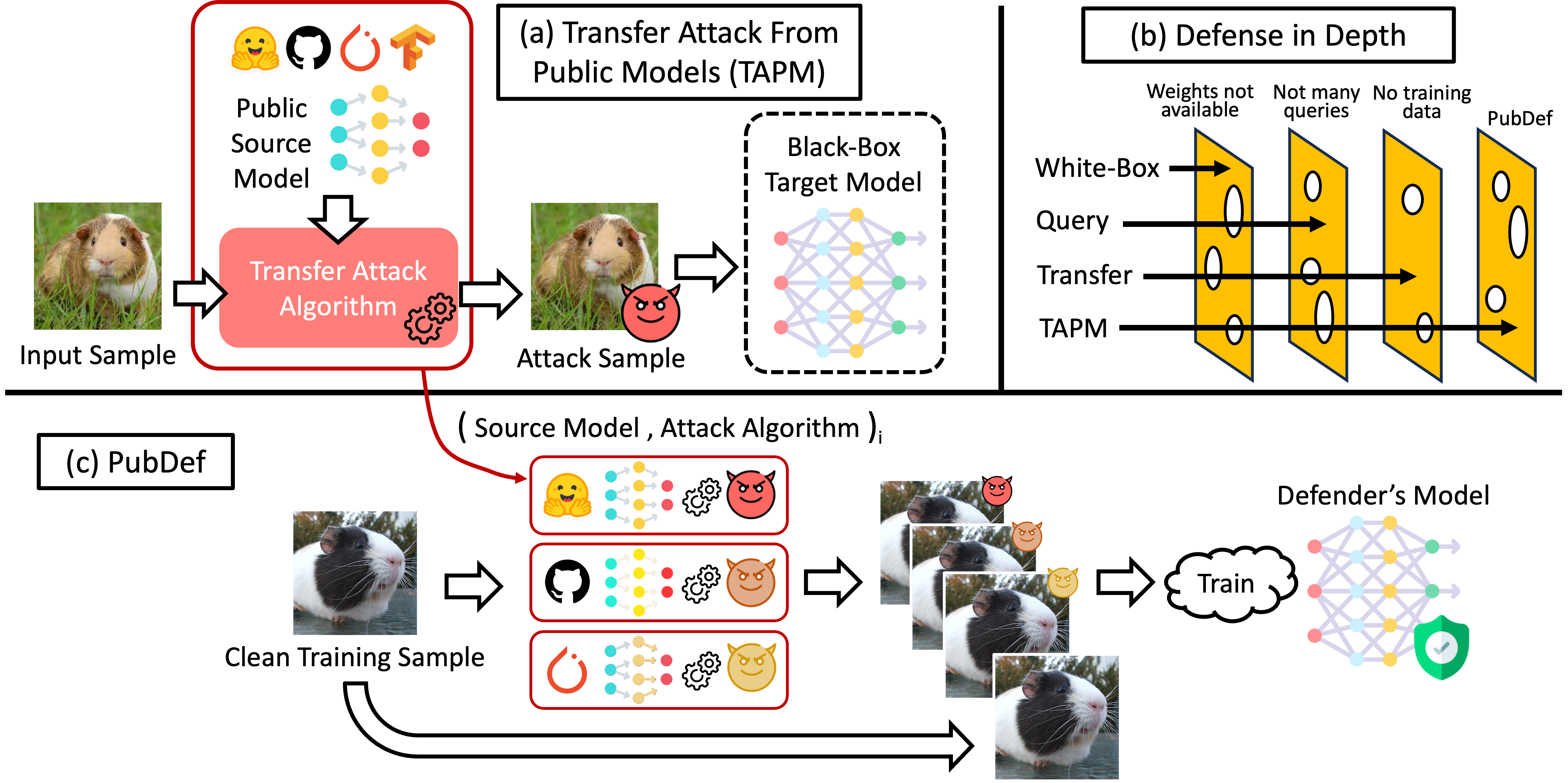
👿 Transfer Attack with Public Source Models
In this work, we propose a new threat model for evasion attacks on ML systems: transfer attacks with public models (TAPM). We consider a low-cost black-box adversary who generates adversarial examples from publicly available models with one of the known attack algorithms. See Figure (a) above.
We emphasize that TAPM is a “weaker” threat model compared to the more well-known ones including the white-box, the query-based, and the standard transfer attacks (where the adversary can freely train a surrogate model). However, TAPM attack is the cheapest to carry out so it is the one that we expect to be the most prevalent in practice and the near future. In contrast, the other three attack threat models require much higher expertise and make unrealistic assumptions about the attacker’s capability. Often, this makes them easy to stop with simple system-level defenses, e.g., simply keeping the model secret stops white-box attacks—see the Swiss cheese model in Figure (b). TAPM makes little assumptions about the attacker, and no system-level defense can stop it.
🛡 PubDef
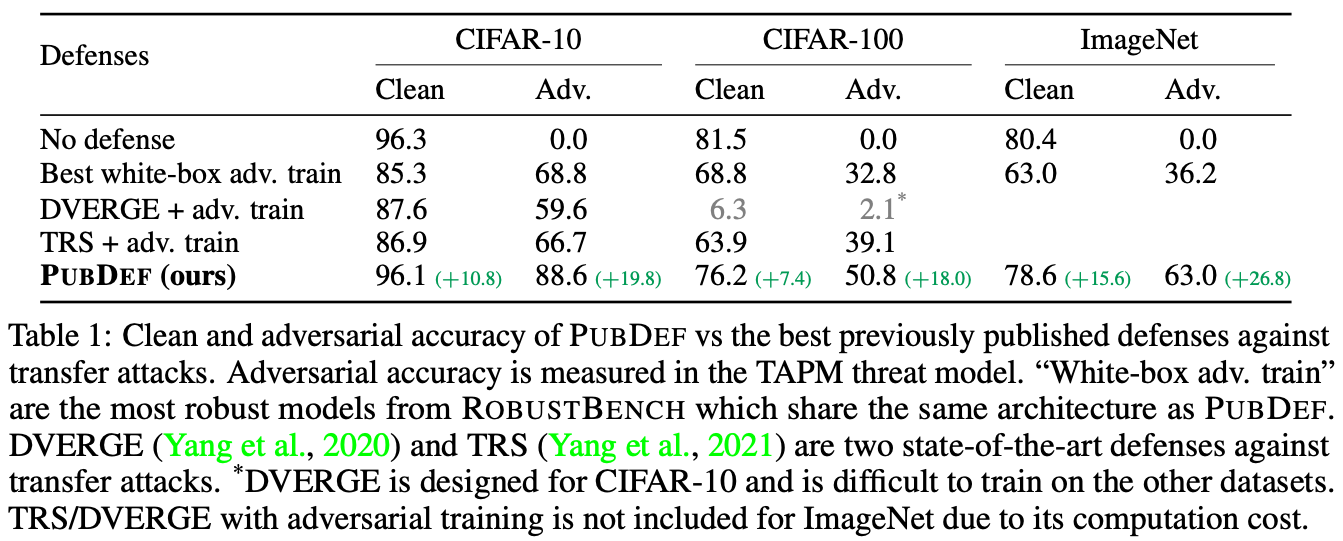
Our defense, PubDef, trains the defended model to resist transfer attacks generated from several publicly available source models. PubDef is robust to a wide range of transfer attacks, including both those from source models that were trained against and others that were not trained against, while also maintaining high clean accuracy. Table 1 below highlights the results in comparison to the baselines.
Each of the PubDef models is trained against PGD adversarial examples generated from only a handful of source models (four for CIFAR-10 and three for CIFAR-100 & ImageNet) as well as benign samples (see Figure (c)).
However, PubDef models are robust to a wide range of transfer attacks across 24 source models and 11 attack algorithms (264 in total).
The 24 source models are gathered from various public repositories including Hugging Face, RobustBench, timm, and a few other Github projects [1, 2] to ensure diversity in terms of both architectures and training methods.
PubDef achieves 18–27 (resp. 7–16) percentage points higher adversarial (resp. clean) accuracy than the best adversarially trained models with the same architecture from RobustBench. It also loses only 0, 5, and 2 percentage points on the clean accuracy compared to the undefended models.
PubDef is motivated by a game-theoretic perspective on adversarial robustness. We use the discrete choices over the source models and the transfer attack algorithms as both the attacker’s and the defender’s strategies. We refer the readers to the paper for more details.
🥡 Takeaways
- Threat model matters. The success of PubDef in the TAPM threat model makes us more optimistic about the security implications of adversarial attacks. There is hope for a secure systems in practice with the right combination of ML-based and system-based defenses.
- Surprisingly, it generalizes. The fact that we can train a PubDef model to be robust to a wide range of transfer attacks from only a small set of them is surprising to us. This implies that there is greater similarity among the models as well as the attacks than we expected.
- This is NOT a reason to stop working on the white-box robustness. PubDef does not provide any white-box robustness as far as we know. White-box robustness is still the be-all and end-all of adversarial robustness and the goal we should strive for. But achieving it under a practically acceptable cost is still a long way to go (if it is achievable at all). In the meantime, we need to be prepared for practical attacks which may come sooner than we have anticipated given the current progress in AI.