Mark My Words
November 30, 2023
TL;DR: LLM Watermarking techniques are ready for deployment. We propose a benchmark for evaluating LLM watermarks, focusing on three main metrics: quality, size (the number of tokens needed to detect a watermark), and tamper-resistance. We compare four schemes from the literature, and find the best to be Kirchenbauer et al. [1]. It can watermark Llama2-7B-chat with no perceivable loss in quality in under 100 tokens, and with good tamper-resistance to simple attacks, regardless of temperature.
Authors: Julien Piet, Chawin Sitawarin, Vivian Fang, Norman Mu, David Wagner
Abstract
The capabilities of large language models have grown significantly in recent years and so too have concerns about their misuse. In this context, the ability to distinguish machine-generated text from human-authored content becomes important. Prior works have proposed numerous schemes to watermark text, which would benefit from a systematic evaluation framework. This work focuses on text watermarking techniques — as opposed to image watermarks — and proposes a comprehensive benchmark for them under different tasks as well as practical attacks. We focus on three main metrics: quality, size (e.g. the number of tokens needed to detect a watermark), and tamper-resistance. Current watermarking techniques are good enough to be deployed: Kirchenbauer et al. [1] can watermark Llama2-7B-chat with no perceivable loss in quality in under 100 tokens, and with good tamper-resistance to simple attacks, regardless of temperature. We argue that watermark indistinguishability is too strong a requirement: schemes that slightly modify logit distributions outperform their indistinguishable counterparts with no noticeable loss in generation quality. We publicly release our benchmark.
Metrics
Our benchmark generates 300 outputs for the watermarked model. It relies on three metrics:
-
Quality provides an average rating of all generated text. Each output is rated by Llama2, prompted to provide a score quantifying the quality of the generation.
-
Watermark Size measures the median number of tokens needed to detect the watermark under a p-value of 0.02. A lower size represents a more efficient watermarking scheme.
-
Tamper-Resistance quantifies the ability of a watermarking scheme to resist output tampering. We use a suite of standard attacks to perturb each output. Each attack removes the watermark from a percentage of outputs, at the cost of a loss in output quality. We use the area under the trade-off curve as our tamper-resistance metric. Values are normalized, and the higher the value, the more robust the watermark.
Schemes

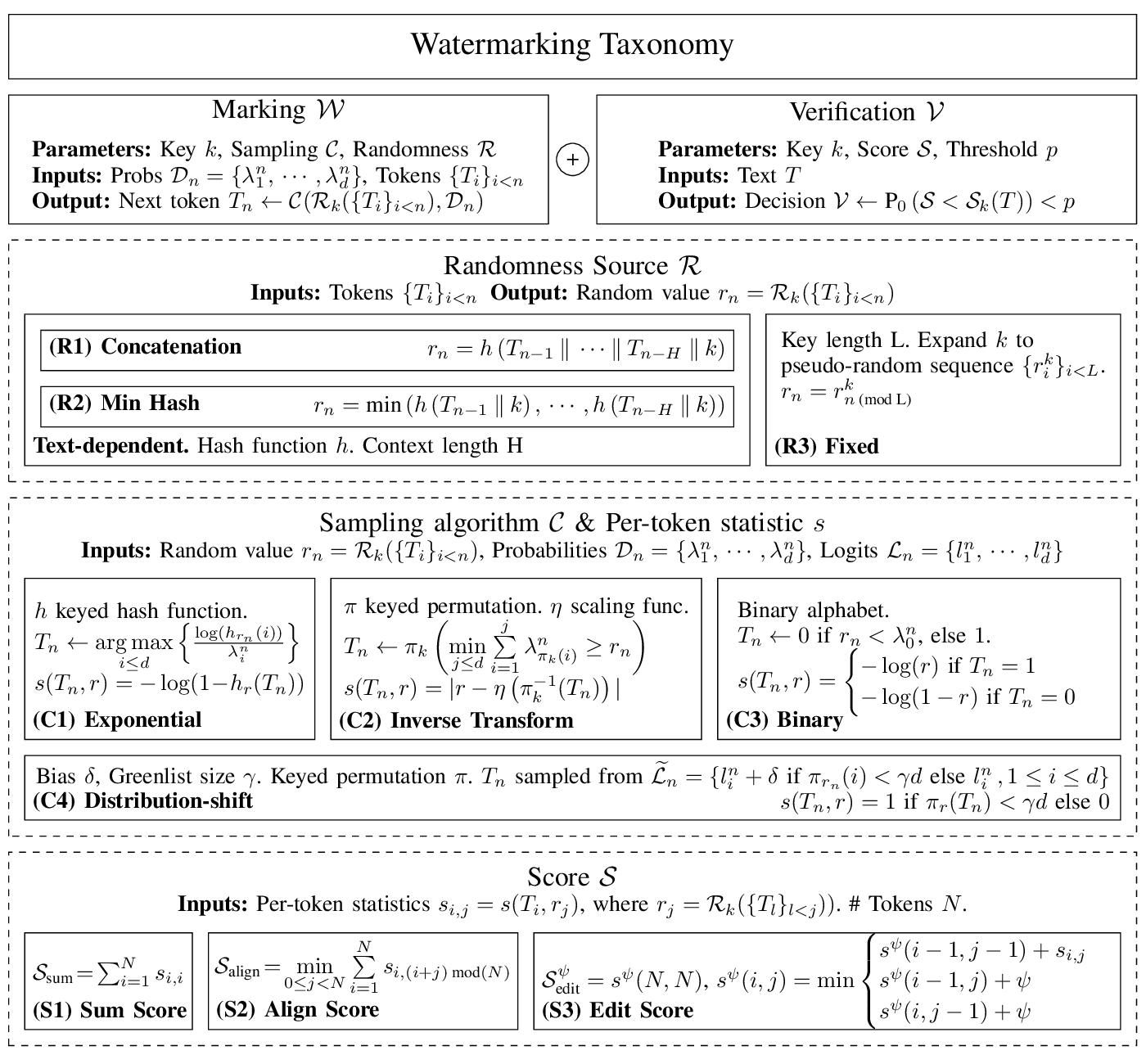
Watermarking schemes are made up of a marking procedure and of a verification procedure. The marking procedure uses a pseudo-random number, seeded by a secret key, to sample tokens according to a predefined sampling strategy.
We analyzed schemes from the litterature released prior to August 2023. We broke them down into four sampling strategies and two pseudo-random sources.
Sampling strategies
- Exponential Introduced by Aaronson and Kirchner [2]. Relies on selecting tokens that maximize a hash function.
- Distribution-Shift Introduced by Kirchenbauer et al. [1]. Favors tokens from a greenlist.
- Binary Introduced in Christ et al. [3]. Converts the token distribution to a binary alphabet.
- Inverse Transform Introduced in Kuditipudi et al. [4]. Selects tokens using inverse transform sampling.
Pseudo-random sources
- Text-Dependent Introduced by Aaronson and Kirchner [2], used by Kirchenbauer et al. [1] and Christ et al. [3]. Hashes a window of prior tokens (either their concatenation, or their minimum), along with the secret key, to generate a pseudo-random value.
- Fixed Introduced by Kuditipudi et al. [4]. Expands the secret key intro a key sequence.
Results
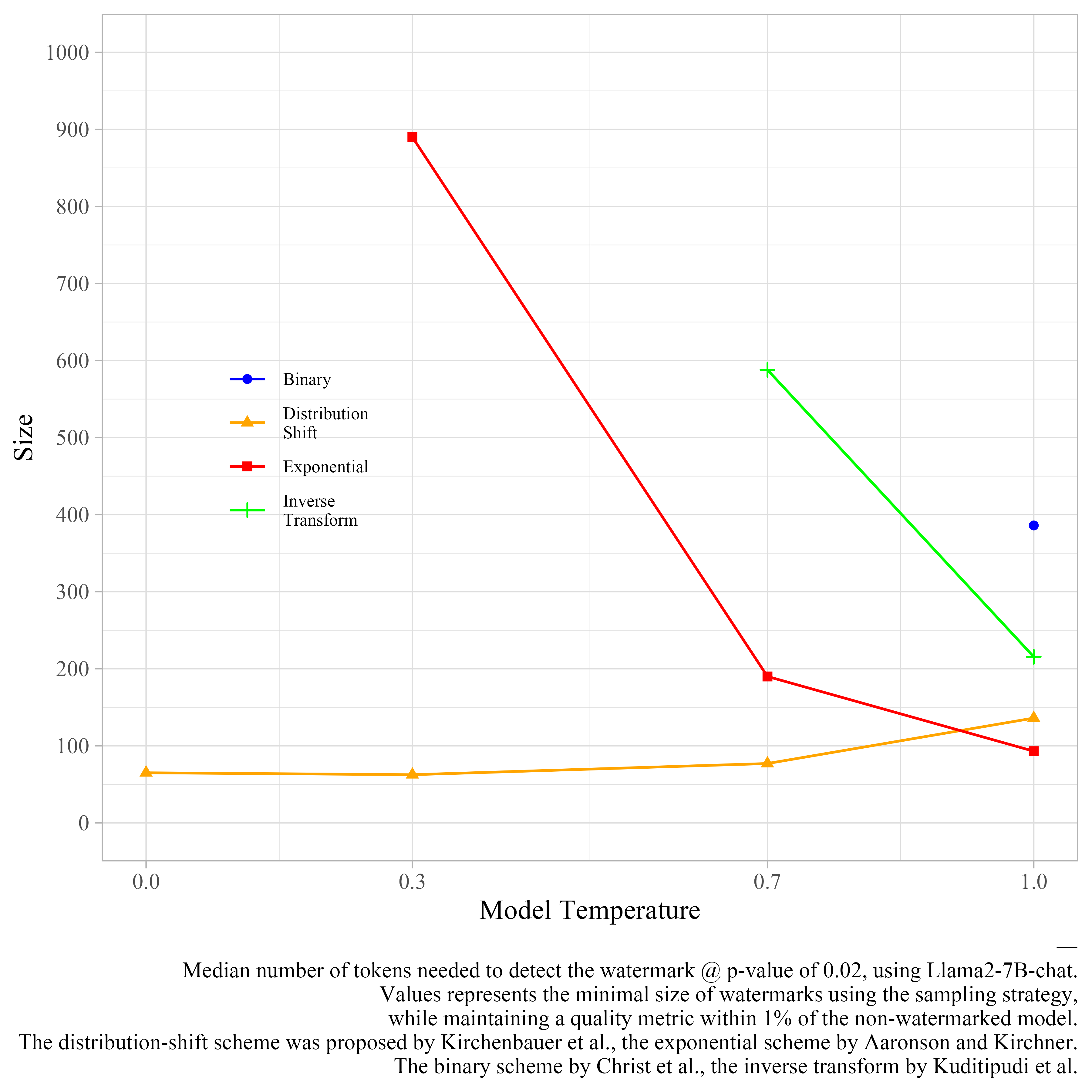
We find the best watermark to be using the distribution-shift sampling with text-dependent randomness. It can watermark Llama2-7B-chat in under 100 tokens at a p-value of 0.02, regarless of the temperature.
At a temperature of 1, the exponential scheme has a slightly smaller size.
Tamper-resistance
The distribution-shift mark is still detectable on 1000-token generations after using a translation attack in about 50% of cases, with near-optional quality and a size under 100 tokens.
You can find more details about our results on all schemes as well as watermarking parameter recommendations in our paper.
Design space
We express all previous LLM watermarking schemes as part of a unified framework, detailed below.
Takeaways
Our empirical analysis demonstrates existing watermark- ing schemes are ready for deployment, providing effective methods to fingerprint machine-generated text. Notably, we can watermark Llama 2, a low-entropy model, in under 100 tokens with minimal quality loss. The tamper-resistance of some watermarks adds credibility to their real-world applications.
We challenge the perceived necessity for watermark indistinguishability: the solution proposed in Kirchenbauer et al. [1] can watermark models more efficiently than alternatives without degrading the model’s quality, despite not being provably indistinguishable.
Finally, we provide recommendations for parameter selection and a benchmark to compare existing and future watermarking schemes. We release our code in the hope it encourages further discussion and helps reach consensus on the desirable properties of watermarking schemes for large language models.
References
[1] J. Kirchenbauer, J. Geiping, Y. Wen, J. Katz, I. Miers, and T. Goldstein, “A watermark for large language models,” in Proceedings of the 40th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, and J. Scarlett, Eds., vol. 202. PMLR, Jul. 2023, pp. 17 061–17 084. https://proceedings.mlr.press/v202/kirchenbauer23a.html
[2] S. Aaronson and H. Kirchner, “Watermarking GPT outputs,” Dec. 2022. https://www.scottaaronson.com/talks/watermark.ppt
[3] M. Christ, S. Gunn, and O. Zamir, “Undetectable watermarks for language models,” Cryptology ePrint Archive, Paper 2023/763, 2023. https://eprint.iacr.org/2023/763
[4] R. Kuditipudi, J. Thickstun, T. Hashimoto, and P. Liang, “Robust distortion-free watermarks for language models,” Jul. 2023. http://arxiv.org/abs/2307.15593